Automated Program Testing
The general research goal here is to utilize formal specifications
such as JML and OCL to make program testing more automatic and
complete, which is of substantial importance to the software
industry. Two different but related threads of research are being
performed. The first thread focuses on automating test oracles that
determine test outcomes, test successes or failures. The earliest and
seminal work is the connection between JML specifications and JUnit
tests and using the former as test oracles [Cheon and Leavens
2002]. The key idea is to use the precondition of a method's
specification to filter invalid test data; this is done by
distinguishing precondition violations that happen on entry to the
method under test from those that happen within the code of the method
under test. This work made a tremendous impact on the formal methods
community, for it helps make formal specifications a useful tool in
unit testing. The approach was adapted for other formal notation such
as OCL and implementation techniques such as AspectJ and Java
annotations [Cheon and Avila 2010] [Cheon 2014].
The other thread of research focuses on automatic test data
generation. One problem is that the state of an object is hidden and
accessible only through a set of exported or public methods and thus
making it challenging to construct a test object of an interesting or
desired state; hidden state variable cannot be manipulated
directly. An object must be constructed indirectly as a sequence of
method invocations, preceded by a constructor invocation, and each
such invocation has to satisfy the assumption that the invoked method
makes about its arguments, called a method precondition. We have been
investigating different strategies for constructing test data
automatically, including random testing [Cheon 2007] [Cheon and Rubio
2007], constraint solving [Cheon and Cortes, et al., 2008), genetic
algorithms [Cheon and Kim 2006] [Kim and Cheon 2008] [Flores and Cheon
2011], pairwise testing [Flores and Cheon 2011], and hand-written
annotations [Cheon 2014].
The strengths of this approach is that it can be fully
automated, eliminates subjectiveness in constructing test data, and
increases the diversity of test data. However, the weakness is that
randomly generated tests may not satisfy a program's assumptions such
as method preconditions. In our experiment, for example, depending on
the complexity of method preconditions, 99% of randomly-generated
method invocation sequences failed to build test objects successfully
[Cheon 2007] [Cheon and Rubio 2007]. To remedy this, we blended random
testing with constraint solving to improve the efficiency of
generating valid test data while preserving diversity. For domains
such as objects, we generate input values randomly; however, for
values of finite domains such as integers, we represent test data
generation as a constraint satisfaction problem by solving constraints
extracted from the precondition of the method under test. In our
experimental evaluation we observed an average improvement of 80 times
without decreasing test data diversity, measured in terms of the time
needed to generate a given number of valid test cases.
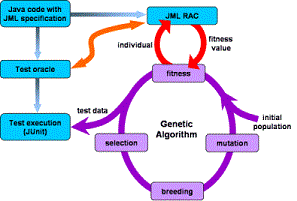 We also applied evolutionary approaches such as genetic algorithms to
test data generation [Cheon and Kim 2006]. The search space is the
input domain of the program under test. And the search starts with an
initial set of test cases that are typically generated randomly, and
then evolves them into new generations by applying operations inspired
by genetics and natural selection, such as selection, crossing, and
mutation. The process is repeated until a solution-a set of test cases
that satisfy the testing criterion-is found or a certain stopping
condition, e.g., the maximum number of iterations, is met. The search
is guided by a fitness function that calculates the fitness values of
the individuals in the generation in that the fitter ones have a
higher chance to survive and thus evolve into the next
generation. Thus, the effectiveness of an evolutionary testing is
determined in part by the quality of the fitness function. We proposed
a new approach to defining fitness functions for evolutionary testing
that allows one to use such an intuition as "choosing the one with the
shortest length" [Kim and Cheon, 2008]. The core idea of our approach
is to use the behavioral specification of a method to determine the
goodness (or fitness) of test data. A preliminary experiment shows
that our approach improves the search from 300% up to 800% in terms of
the number of iterations needed to find a solution. We also developed
a new testing framework called PWiseGen that generates pair-wise test
sets using genetic algorithms [Flores and Cheon 2011]. Pairwise
testing is a combinatorial testing technique that tests all possible
pairs of input values. Although, finding a smallest set of test cases
for pairwise testing is NP-complete, pairwise testing is regarded as a
reasonable cost-benefit compromise among combinatorial testing
methods. We formulate the problem of finding a pairwise test set as a
search problem and apply a genetic algorithm to solve it. PWiseGen
produces competitive results compared with existing pairwise testing
tools, and it provides a framework and a research platform for
generating pairwise test sets using genetic algorithms because it is
configurable, extensible, and reusable.
We also applied evolutionary approaches such as genetic algorithms to
test data generation [Cheon and Kim 2006]. The search space is the
input domain of the program under test. And the search starts with an
initial set of test cases that are typically generated randomly, and
then evolves them into new generations by applying operations inspired
by genetics and natural selection, such as selection, crossing, and
mutation. The process is repeated until a solution-a set of test cases
that satisfy the testing criterion-is found or a certain stopping
condition, e.g., the maximum number of iterations, is met. The search
is guided by a fitness function that calculates the fitness values of
the individuals in the generation in that the fitter ones have a
higher chance to survive and thus evolve into the next
generation. Thus, the effectiveness of an evolutionary testing is
determined in part by the quality of the fitness function. We proposed
a new approach to defining fitness functions for evolutionary testing
that allows one to use such an intuition as "choosing the one with the
shortest length" [Kim and Cheon, 2008]. The core idea of our approach
is to use the behavioral specification of a method to determine the
goodness (or fitness) of test data. A preliminary experiment shows
that our approach improves the search from 300% up to 800% in terms of
the number of iterations needed to find a solution. We also developed
a new testing framework called PWiseGen that generates pair-wise test
sets using genetic algorithms [Flores and Cheon 2011]. Pairwise
testing is a combinatorial testing technique that tests all possible
pairs of input values. Although, finding a smallest set of test cases
for pairwise testing is NP-complete, pairwise testing is regarded as a
reasonable cost-benefit compromise among combinatorial testing
methods. We formulate the problem of finding a pairwise test set as a
search problem and apply a genetic algorithm to solve it. PWiseGen
produces competitive results compared with existing pairwise testing
tools, and it provides a framework and a research platform for
generating pairwise test sets using genetic algorithms because it is
configurable, extensible, and reusable.
To summarize, our research has contributed to making testing more
automatic and complete, which is of substantial importance to the
software industry.
-
Yoonsik Cheon,
Writing Self-testing Java Classes with SelfTest,
Technical Report 14-31, Department of Computer Science,
University of Texas at El Paso, El Paso, TX, April 2014.
[PDF]
-
Pedro Flores and
Yoonsik Cheon,
PWiseGen: Generating Test Cases for Pairwise Testing
Using Genetic Algorithms,
2011 IEEE International Conference
on Computer Science and Automation Engineering (CSAE 2011),
June 10-12, 2011, Shanghai, China, pages 747-752,
IEEE Computer Society.
[DOI:
10.1109/CSAE.2011.5952610]
-
Yoonsik Cheon and
Carmen Avila.
Automating Java Program Testing Using OCL and AspectJ.
ITNG 2010: Seventh International Conference on Information
Technology, April 12-14, 2010, Las Vegas, NV,
pages 1020-1025, IEEE Computer Society.
[DOI:
10.1109/ITNG.2010.123]
-
Carmen Avila, Amritam Sarcar,
Yoonsik Cheon, and
Cesar Yeep.
Runtime Constraint Checking Approaches for OCL,
A Critical Comparison,
22nd International Conference
on Software Engineering and Knowledge Engineering (SEKE 2010),
July 1-3, 2010, San Francisco, CA,
pages 393-398.
[PDF]
-
Yoonsik Cheon,
Carmen Avila, Steve Roach,
and Cuauhtemoc Munoz.
Checking Design Constraints at Run-time Using OCL and AspectJ,
International Journal
of Software Engineering,
2(3):5-28, December 2009.
[PDF]
-
Yoonsik Cheon,
Antonio Cortes,
Martine Ceberio, and
Gary T. Leavens.
Integrating Random Testing with Constraints for Improved Efficiency
and Diversity.
In Proceedings of SEKE 2008, The 20-th International Conference
on Software Engineering and Knowledge Engineering, July 1-3,
2008, San Francisco, CA,
pages 861-866, July 2008.
[PDF]
-
Myoung Yee Kim and
Yoonsik Cheon.
A Fitness Function to Find Feasible Sequences of Method Calls
for Evolutionary Testing of Object-Oriented Programs.
International Conference on Software Testing,
Verification, and Validation, Norway, April 9-11, 2008,
pages 537-540, IEEE Computer Society.
[DOI:
10.1109/ICST.2008.31]
-
Yoonsik Cheon.
Abstraction in Assertion-based Test Oracles.
In Proceedings of the Seventh International Conference on
Quality Software,
Portland, Oregon, USA, October 11-12, 2007,
pages 410-414, IEEE Computer Society.
[DOI:
10.1109/QSIC.2007.4385528]
-
Yoonsik Cheon.
Automated Random Testing to Detect Specification-Code Inconsistencies.
In Proceedings of the 2007 International Conference on
Software Engineering Theory and Practice,
July 9-12, 2007, Orlando, Florida, U.S.A.,
pages 112-119.
[PDF]
-
Yoonsik Cheon and
Carlos E. Rubio-Medrano.
Random Test Data Generation for Java Classes Annotated with JML
Specifications.
In Proceedings of the 2007 International Conference
on Software Engineering Research and Practice,
Volume II, June 25--28, 2007, Las Vegas, Nevada,
pages 385-392.
[PDF]
-
Yoonsik Cheon and
Myoung Kim.
A Fitness Function for Modular Evolutionary Testing of
Object-Oriented Programs.
In Genetic and Evolutionary Computation Conference,
Seattle, WA, USA, July 8-12, 2006,
pages 1952-1954, ACM Press, 2006.
[PDF]
-
Yoonsik Cheon,
Myoung Yee Kim, and Ashaveena Perumandla.
A Complete Automation of Unit Testing for Java Programs.
Proceedings of the 2005 International Conference on
Software Engineering Research and Practice (SERP '05),
Las Vegas, Nevada, June 27-29, 2005,
pages 290-295, 2005.
[PDF]
-
Yoonsik Cheon and
Gary T. Leavens.
A Simple and Practical Approach to Unit Testing: The JML and JUnit Way.
In Boris Magnusson (ed.), ECOOP 2002 - Object-Oriented Programming,
16th European Conference, Malaga, Spain, June 2002, Proceedings.
Volume 2374 of Lecture Notes in Computer Science, pages 231-255.
Springer-Verlag, 2002.
[PDF]
Our research was supported by the following
research grants.
- Improving Dependability of Software through Rigorous Testing
against Requirements,
Homeland Protection Institute/US Army Space and Missile
Defense Command, Department of Defense, $115,878,
01/22/2008-01/21/2009 (PI: Yoonsik Cheon; Co-PI: Steve Roach)
- Collaborative Research: Unification of Verification and Validation
Methods for Software Systems, National Science Foundation,
CNS-0509299, $167,999, 09/01/2005-08/31/2008 (PI: Yoonsik Cheon;
Co-PI: Patricia J. Teller)
- Automated Testing of Object-Oriented Programs,
UTEP University Research Institute,
$5,100, 09/2004-8/2005 (PI: Yoonsik Cheon)
Last modified: $Id: autotest.html,v 1.7 2019/08/17 19:29:20 cheon Exp $